Immer toll, wenn man viele Dateien umbenennen muss, weil man Kopien anders ordnen möchte, einem bei der Benennung ein Fehler unterlaufen ist oder einem Dateien geliefert worden sind mit nicht nachvollziehbaren Benennung. Bei mir hieß das immer „Happy-Right-Mouseclick“, brauchte Geduld und machte nicht wirklich Spaß.
Viola Voß stellt in der Beitragsreihe #Tools auf dem FachBlog der ULB Münster mit FastRenamer ein kleines, aber leistungsfähiges Werkzeug vor, dass hier Abhilfe schaffen kann.
Screenshots zu annotieren sah bei mir wie folgt aus: Screenshot anfertigen, in ein Bildbearbeitungsprogramm hochladen. Mühsam Emojis, Sticker etc. bei Google suchen, herunterladen, einfügen, bearbeiten, Text anfertigen, als Layer aufbringen, speichern und an der Stelle, wo es gebraucht wurde hochladen. – Also ja, eine Bearbeitung bzw. das Annotieren von Screenshots hat keinen Spaß gemacht, war umständlich und langwierig und sah deshalb meist am Ende langweilig aus, weil nicht alle Arbeitsschritte gemacht werden wollten.
Für die Beispiele habe ich die gleiche Zeit aufgewendet. Sehen Sie selbst.
Annotierter Screenshot des Adventskalenders mit Powerpoint
Es ist sofort ersichtlich: Das ist gemacht mit Powerpoint und deshalb wirken diese Screenshots fast starr und unpersönlich.
Über das angezeigt Menü kann man nun Emojis, Sticker, Pfeile, Striche, Markierungen und Text einfügen.
Die einzelnen Teile lassen sich per Drag&Drop an die richtigen Stellen ziehen und wie Bilder vergrößern und verkleinern.
Farbe und Schriftstil lassen sich individuell anpassen.
Bei mehreren Elementen an einer Stelle kann man auch bestimmen, welches vorne und welches weiter hinten angelegt ist.
Fertig? Bild herunterladen, abspeichern und an der gewünschten Stelle verwenden.
Mit diesem Tool erhält man eine schnelle Möglichkeit am Rechner Screenshots sauber zu annotieren, ohne dass es steif und gewollt aussieht. Viele der Funktionen werden aber durch die Bildbearbeitungsprogramme auf dem Handy mitgeliefert, sodass dort nicht der umständliche Weg über die Webseite von Copy&PasteDesign.com verwendet werden muss.
Anwendungsmöglichkeiten
Da fällt mir die ein oder andere Präsentation ein, die man so im Laufe seines Arbeitslebens hält. Micro-Learning-Einheiten für Kolleg:innen und Nutzer:innen lassen sich damit sicherlich auch gut aufpeppen. Verdeutlichende Grafiken beim Wissensmanagement … Es geht schnell und unkompliziert.
Fazit
Ein Bookmark zu diesem Tool lohnt sich für die alltägliche Arbeit. Wenn Sie das nächste Mal Ihre:r IT-ler:in einen Fehler melden müssen, können Sie dies nun wirklich stilvoll mit einem gut gestalteten Screenshot tun.
Zum Schluss
Damit ist das letzte Türchen dieses Adventskalenders geöffnet. Ich persönlich habe viele neue Tools dadurch kennengelernt und einige mir wieder in Erinnerung gerufen.
Einen herzlichen Dank an Viola Voß (Viola’s Blog, ULB Fachblog der UB Münster), Philipp Zumstein (Literaturverwaltung), Aaron Tay und Barbara Fischer (Blog der GND), ohne die dieser Adventskalender nicht zustande gekommen wäre oder viele Türchen leer geblieben wären. Ihre Beiträge und Impulse haben den Kalender mit Leben gefüllt.
Und letztlich bleibt mir für dieses Jahr nur noch, Ihnen allen ein paar besinnliche Feiertage, hoffentlich im Kreis ihrer Lieben, zu wünschen. Kommen Sie erholt, gesund und munter ins neue Jahr 2021.
Linksklick, Rechtsklink, Scrollen – mit einer Mouse sind das Standardfunktionen. Kann eine Mouse denn mehr? Nun mit X-Mouse Button Control kann man mehr aus seiner Mouse herausholen. Dieses Programm stellt Viola Voß im 23. Türchen im FachBlog der ULB Münster vor.
Screenshots sind unverzichtbar. Ein Bildschirmfoto anzufertigen kann aber umständlich sein. Viola Voß stellt in ihrem Blog hinter Türchen 22 dafür passende Werkzeuge vor.
Texte wiederholt eingeben? Da eine Schlussfloskel hier eine kilometerlange URL und dann gleich nochmal beides an anderer Stelle in einem anderen Programm? Das geht bequemer.
Mit AutoHotKey stellt Viola Voß ein weiteres kleines, aber recht hilfreiches Tool im FachBlog der ULB Münster vor.
Tatsächlich tun sie dies schon eine ganze Weile, aber der kürzlich erschienene Preprint „Open is not forever: a study of vanished open access journals“ beleuchtete die Problematik, dass Zeitschriften aus dem Internet verschwunden sind, die aber nicht sicher langzeitarchiviert wurden (nicht alle Zeitschriften fallen unter LOCKSS oder ähnliche Programme).
Dieser Blogbeitrag beschreibt den Top-Down-Prozess, der im Ergebnis zu Fatcat führte.
Top-Down: Using the bibliographic metadata from sources like CrossRef to ask whether that article is in the Wayback Machine and, if it isn’t trying to get it from the live Web. Then, if a copy exists, adding the metadata to an index.
Außerdem wird ein Bottom-up-Ansatz beschrieben, der mich (Aaron Tay, Anm. d. Übers.) daran erinnert, wie Google Scholar es tut. Dies ist natürlich sehr schwierig.
Bottom-up: Asking whether each of the PDFs in the Wayback Machine is an academic article, and if so extracting the bibliographic metadata and adding it to an index.
Ich (Aaron Tay, Anm. d. Übers.) habe noch keine vollständige Überprüfung von Fatcat durchgeführt, aber es ist im Wesentlichen eine
versioned, publicly-editable catalog of research publications: journal articles, conference proceedings, pre-prints, blog posts, and so forth. The goal is to improve the state of preservation and access to these works by providing a manifest of full-text content versions and locations.
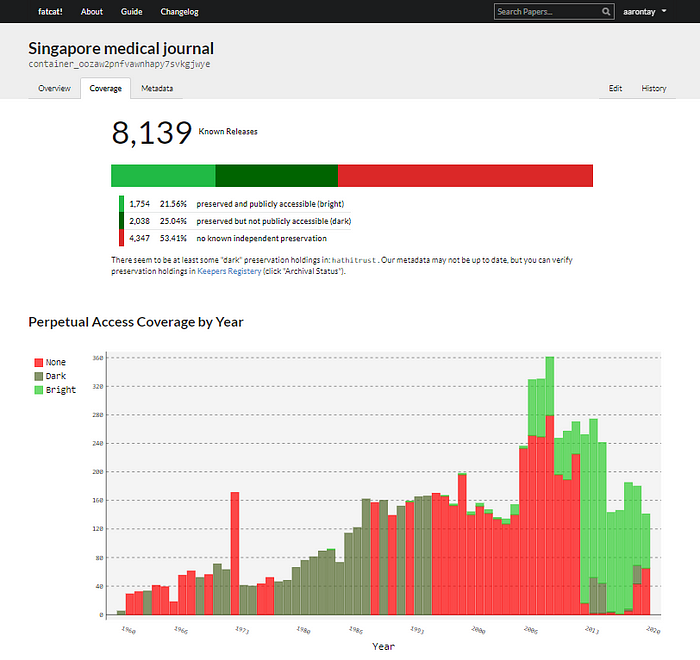
Neben anderen Features wird auf Datei/Element-Ebene verfolgt, ob der Artikel bereits ordnungsgemäß archiviert wird, egal, ob dies über ein geschlossenes Archiv wie (LOCKSS) oder eine offnes Archive (z.B. Hathitrust, durch das Internet Archive selbst) erfolgt, indem die Daten von Websites wie Keepers Registery herangezogen werden etc.
Neben Fatcat, dem Internet Archive gibt es auch ein Internet Archive Scholar (zurzeit unter https://scholar-qa.archive.org/).
Wie unterscheidet sich dieses vom Fatcat? Im wesentlichen listet Fatcat all Beiträge auf, auch wenn diese nur Metadaten enthalten, während das Internet Archive Scholar nur Volltexte anzeigt.
Ich frage mich (Aaron Tay, Anm. d. Übers.), ob es eine gute Idee wäre, Ihre Google Scholar-Suchanfragen damit zu ergänzen, um festzustellen, ob Sie etwas nicht gefunden haben.
Verbesserte „Zitationsanzeige“ in Semantic Scholar
Die „Zitiert durch“-Suche bei Google Scholar ist IMHO (Aaron Tay, Anm. d. Verf.) eines der stärksten Features der Suchmaschine. Sie erlaubt die Einrichtung einer automatischen Benachrichtigung, und was noch wichtiger ist, sie ermöglicht Ihnen die „Suche in zitierenden Artikeln“, eine sehr leistungsstarke Funktion zum schnellen Herausfiltern von interessanten Zitationen, wenn es Tausende von Zitationen für ein bahnbrechendes Paper gibt.
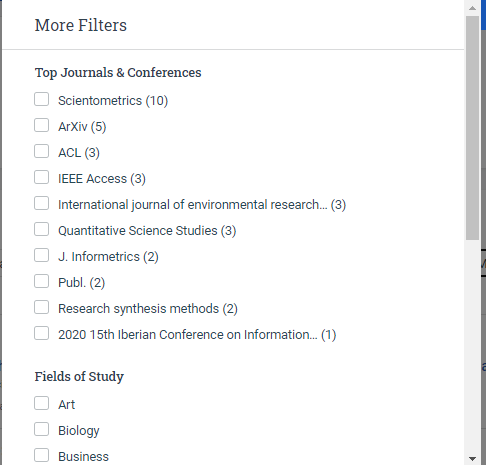
Ein Teil der Gründe, warum die „Suche innerhalb der zitierenden Artikel“ in Google Scholar so leistungsfähig ist, ist dass Google Scholar in den meisten Fällen den Volltext besitzt, sodass Sie 1.000+-Artikel nach einem ziemlich spezifischen Begriff durchsuchen können, etwas, dass Sie in den meisten anderen Suchmaschinen aufgrund des fehlenden Volltextes nicht tun können. Allerdings verfügen andere Suchrivalen wie Semantic Scholar über mehr Metadaten. Dieses neue Charakteristikum ermöglicht es Ihnen ebenfalls innerhalb von Zitaten zu suchen, erlaubt Ihnen aber auch, nach
Art der Veröffentlichung (Buch, Zeitschriftenartikel etc.),
Titel der Zeitschrift/Konferenz,
Studiengebiet (z.B. Kunst, Biologie),
Autor,
und mehr
zu filtern.
Ich (Aaron Tay, Anm. d. Verf.) probiere es immer noch aus, aber ich vermute, dass Nr. 2 Zitationstyp und Nr. 5 Studiengebiete die interessanteste Filter sein können, wenn Sie eine Menge Zitationen durchgehen müssen. Allerdings ist es etwas frustrierend, dass, während die anderen Filter nur Optionen anzeigen, die mindestens ein Element haben, die „Studiengebiete“ alle aufgelistet werden, und wenn Sie auf einige davon klicken, erhalten Sie keine Ergebnisse.
Dieser Blogbeitrag ist Teil der der Adventskalender Blogparade 24 Tools aus dem Netz im Einsatz für Bibliotheken#netzadvent2020:
RSS-Feeds sind immer wieder ein Thema, was gnadenlos unterschätzt wird. Viola Voß stellt in ihrem Adventskalenderbeitrag verschiedene Möglichkeiten zum abonnieren von RSS-Feeds vor. Danben lädt sie zu einer kleinen Bastelaktion ein und zeigt, wie man RSS-Feeds für Seiten ohne RSS-Feeds zusammenbasteln kann.
Viola Voß stellt ein weiteres nützliches Tool vor, welches am Ende Zeit sparen kann. Der Beitrag erscheint im Fachblog der ULB Münster, in dem es neben fachlichen Hinweisen auch immer mal wieder Tipps für das wissenschaftliche Arbeiten gibt.
Dies Website verwendet Cookies.
Notwendige Cookies helfen dabei, eine Webseite nutzbar zu machen, indem sie Grundfunktionen wie Seitennavigation und Zugriff auf sichere Bereiche der Webseite ermöglichen. Die Webseite kann ohne diese Cookies nicht richtig funktionieren.
Die Website verwendet unter Umständen auch nicht erforderliche Cookies, um Inhalte und Anzeigen zu personalisieren, Funktionen für soziale Medien anbieten zu können und die Zugriffe auf unsere Website zu analysieren.
This cookie is set by GDPR Cookie Consent plugin. It records the default button state of the corresponding category. It works only in coordination with the primary cookie. - This cookie stores no personal Data.
viewed_cookie_policy
persistent
1 year
This cookie is set by GDPR Cookie Consent plugin. The primary cookie that records the user consent for the usage of the cookies upon ‘accept’ and ‘reject.’ It does not track any personal data and is set only upon user action (accept/reject).
Einige Cookies sind für den reibungslosen Betrieb der Website unverzichtbar. Notwendige Cookie sind zur Absicherung der Basisfunktionalitäten und Sicherheitsfeatures der Website unerlässlich. Diese Cookies speichern keine persönlichen Daten.
Zu dieser Kategorie zählen alle Cookies, die nicht wirklich für das Funktionieren der Website notwendig sind und genutzt werden, um persönliche Daten zu Analysezwecken, für Werbung oder andere eingebundene Inhalte zu ermitteln und weiterzugeben.
Diese nicht-notwendigen Cookies geben Informationen zu Ihrer Verwendung dieser Website an die entsprechenden Webdienste für soziale Medien, Werbung und Analysen weiter. Diese Webdienste führen die Informationen möglicherweise mit weiteren Daten zusammen, die Sie ihnen bereitgestellt haben oder die diese im Rahmen Ihrer Nutzung der Dienste gesammelt haben.