Wir sehen ständig neue Forschungsinstrumente im Zusammenhang mit Discovery Services, hier sind einige weitere, denen ich begegnet bin. Ich werde sie mit nur wenigen Kommentaren versehen
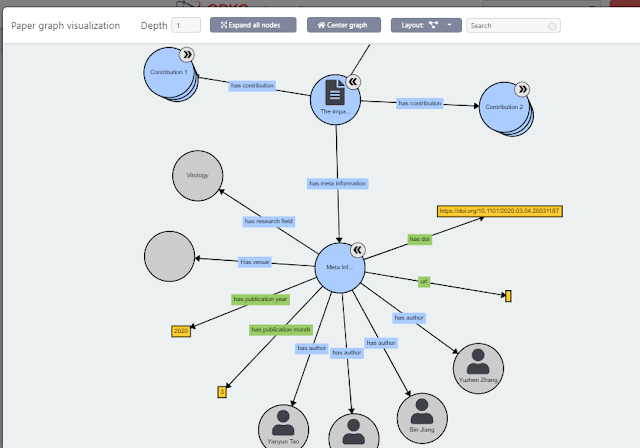
Der Open Knowledge Research Graph unterscheidet sich auf dem Papier nicht sehr von anderen Wissenschaftsgraphen da draußen wie etwa der OpenAire Knowledge Graph, der Project Freya PID Graph. Der Kernpunkt ist aber meiner Meinung nach, dass der Open Knowledge Research Graph nicht nur Metadaten des Papiers erfassen wie z.B. Titel, Autor, DOI, Zeitschriftentitel, sondern auch den Beitrag („contribution“) des Papiers, die Methodologie usw.
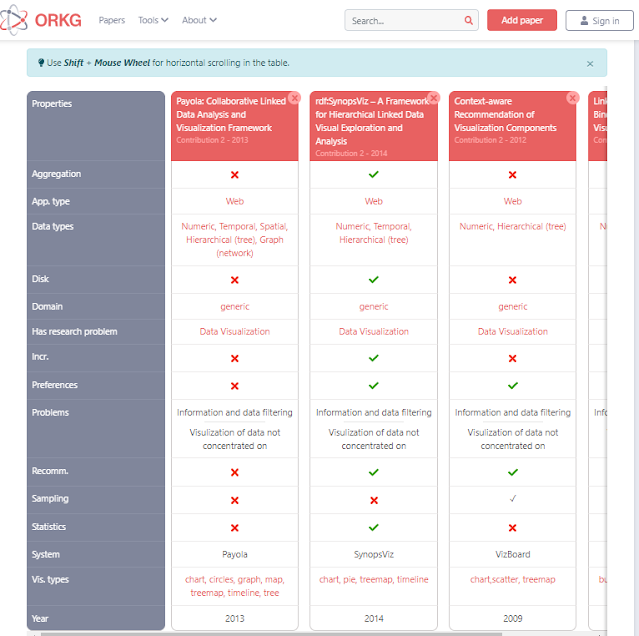
Dies ermöglicht interessante Funktionen wie die automatische Generierung von Vergleichstabellen:
Interessanterweise scheint erwartet zu werden, dass Menschen den Beitrag entsprechend auszeichnen. Dahingegen verfolgen Startups, die wie Scholarcy um maschinelles Lernen herum aufgebaut sind, den Ansatz, die meiste Arbeit mit Maschinen zu erledigen.
Dies ist bis zu einem gewissen Grad in Analogie zu der von Crossref geleisteten Arbeit, im Gegensatz zu den Ansätzen von Google Scholar und Microsoft Academic, die sich eher auf die maschinelle Extraktion verlassen.
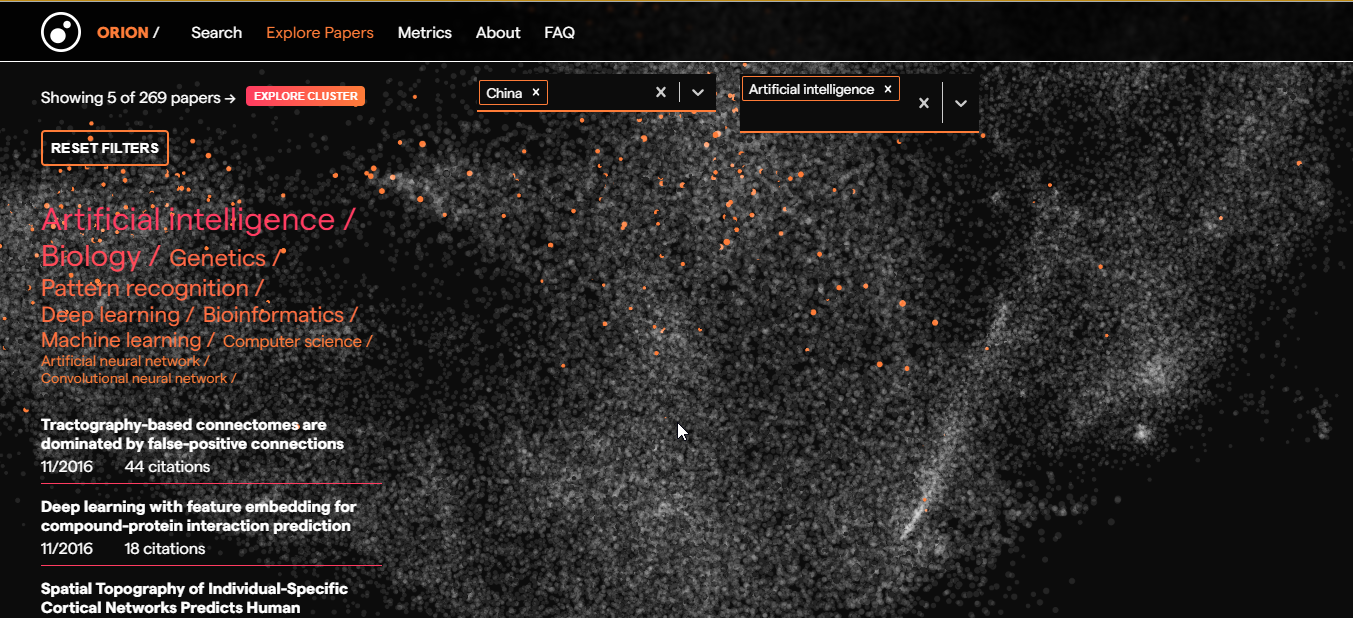
Zu guter Letzt ist die sehr ausgefallene https://www.orion-search.org/ zu erwähnen. Die Visualisierungsoberfläche erinnert mich daran, ein 4X-Weltraum-Strategiespiel zu spielen, bei dem man im 3D-Raum schwenken und zoomen kann.
Orion hat auch eine ungewöhnliche Metrik mit den Achsen Forschungsvielfalt („research diversity“) und Geschlechtervielfalt („gender diversity“).
Zu beachten ist, dass die Orion-Demo auf eine bestimmte Anzahl von Arbeiten beschränkt ist und nicht als disziplinübergreifende Datenbank verwendet werden kann.
Dieser Blogbeitrag ist Teil der der Adventskalender Blogparade 24 Tools aus dem Netz im Einsatz für Bibliotheken#netzadvent2020:
Klassifikation von Zitationen und Suchmöglichkeiten
scite ist eine interessante Zitationsdatenbank, welche Zitationen mit Hilfe von maschinellem Lernen danach klassifiziert, ob sie den Artikel unterstützen („support“), anfechten/ablehnen („dispute“) oder nur erwähnen („mention“).
Aktuell hat scite die Abdeckung der Publikationen erheblich erweitert und ist auf 700 Millionen „intelligente Zitate“ angewachsen. Ein Vergleich mit traditionellen Zitationsdatenbanken ist schwierig, aber ich denke, dass die Core Collection des Web of Science üblicherweise auf etwa 1 Milliarde geschätzt wird, also rücken wir näher.
Was die Funktionen betrifft, so hat scite eine Reihe von Features hinzugefügt. Einige (auch einfache) sehen für mich recht nützlich aus. Zum Beispiel erweiterte Suchfilter, Facetten und Sortieroptionen vereinfachen es, das Gesuchte zu finden. Sie haben auch damit begonnen, den Retraction-Status aufzunehmen, wobei ich mir nicht sicher bin, um welche Quelle es sich handelt und wie genau diese ist.
Bei den von scite angepriesenen Badges und Journal-Dashboards in scite hingegen sind einige besorgt über die Auswirkungen der Verwendung einer weiteren neuen und nicht so gut verstandenen Metrik, die für die Auswertung verwendet wird, mit der zusätzlichen Komplikation des maschinellen Lernens.
Visualisierung von Zitationsnetzwerken
Meine persönliche Meinung ist, dass es zwar verfrüht wäre, scite für Bewertungsmetriken zu verwenden, aber wahrscheinlich ist es eher vertretbar, scite für die Untersuchung von Literatur zu verwenden. Zugegeben, es gibt unklare Verzerrungen, die sich aus der Verwendung von scite dafür ergeben könnten, aber ich würde behaupten, dass es nicht viel schlimmer ist, als Papiere mit anderen zitationsbasierten Methoden zu betrachten oder sich auf Black-Box-Algorithmen von Suchmaschinen zu verlassen.
Daher sehe ich der Einführung von Visualisierungsmöglichkeiten in scite mit großem Interesse entgegen. Das Versprechen hier ist, dass man die Literatur erkunden kann, indem man die Knotenpunkte danach erweitert, ob ein Papier unterstützende, bestreitende oder auch nur erwähnende Zitate zum ersten Startpapier hat, mit dem man beginnt.
Ich persönlich fand die Benutzeroberfläche anfangs nicht allzu intuitiv, aber als ich mir das obige YouTube-Video ansah, wurde sie klarer und bald schon zur Selbstverständlichkeit.
Man klickt auf „show visualization“ (Visualisierung anzeigen) und standardmäßig werden das ausgewählte Papier und die unterstützenden Zitate (in grün) und die widersprechenden Zitate (in orange) angezeigt. Standardmäßig werden erwähnende Zitate nicht angezeigt, aber man kann sie hinzufügen.
Klickt man dann auf einen Knoten, dann wird er im linken oberen Bereich angezeigt. Mit einem Klick auf das kleine Plus-Symbol daneben kann man den Knoten erweitern.
An diesem Punkt grüble ich noch darüber nach, wie man dies am besten nutzen kann.
Literaturverzeichnis prüfen
Ein weiteres interessantes Feature ist der Referenz-Checker von scite. [TODO Das funktioniert bei mir gerade nicht, wieso?]
Die Idee dabei ist, dass man jedes beliebige Papier hochladen kann, beispielsweise ein Manuskript, das noch nicht veröffentlicht wurde, und scite erstellt einen Bericht ähnlich wie bei den scite-Einträgen für veröffentlichten Papieren in cite selbst.
Referenz-Checker von scite — Hochladen eines Preprints, eines Manuskripts um die Verarbeitung von scite zu erhalten
Die Verarbeitung von scite bedeutet, dass die Referenzen im Literaturverzeichnis auf Retractions geprüft werden und es sichtbar gemacht wird, wie jede Referenz zitiert wurde.
Bericht vom Referenz-Checker
Ich kann mir vorstellen, dass dies nützlich sein kann, wenn man als Gutachter*in schnell einen Überblick darüber erhalten möchte, was und wie zitiert wurde, oder wenn man selbst als Autor*in vor der Einreichung bei einer Zeitschrift einen solchen Überblick haben möchte.
Ein ziemlich interessantes Tool, das zusammen mit diesem verwendet werden kann, ist das Scholarcy Preprint Healthcheck API, das ich in einem anderen Post erwähne. Es extrahiert Affiliationen, zeigt Schlüsselergebnisse auf, berechnet eine fachliche Zuordnung, Statistiken und versucht, Abschnitte zur Datenverfügbarkeit, ethics statement usw. zu identifizieren. Einige Überschneidungen gibt es insofern, als auch auf Retractionen geprüft wird. Was die Literaturangaben anbelangt, so werden sie extrahiert und mit verschiedenen Whitelists oder Quellen wie DOAJ und Crossref verglichen, was meiner Meinung nach nützlich sein kann, wenn man Literaturangaben nach dem Ansehen der Quelle filtern möchte.
Dieser Blogbeitrag ist Teil der der Adventskalender Blogparade 24 Tools aus dem Netz im Einsatz für Bibliotheken#netzadvent2020:
Dies Website verwendet Cookies.
Notwendige Cookies helfen dabei, eine Webseite nutzbar zu machen, indem sie Grundfunktionen wie Seitennavigation und Zugriff auf sichere Bereiche der Webseite ermöglichen. Die Webseite kann ohne diese Cookies nicht richtig funktionieren.
Die Website verwendet unter Umständen auch nicht erforderliche Cookies, um Inhalte und Anzeigen zu personalisieren, Funktionen für soziale Medien anbieten zu können und die Zugriffe auf unsere Website zu analysieren.
This cookie is set by GDPR Cookie Consent plugin. It records the default button state of the corresponding category. It works only in coordination with the primary cookie. - This cookie stores no personal Data.
viewed_cookie_policy
persistent
1 year
This cookie is set by GDPR Cookie Consent plugin. The primary cookie that records the user consent for the usage of the cookies upon ‘accept’ and ‘reject.’ It does not track any personal data and is set only upon user action (accept/reject).
Einige Cookies sind für den reibungslosen Betrieb der Website unverzichtbar. Notwendige Cookie sind zur Absicherung der Basisfunktionalitäten und Sicherheitsfeatures der Website unerlässlich. Diese Cookies speichern keine persönlichen Daten.
Zu dieser Kategorie zählen alle Cookies, die nicht wirklich für das Funktionieren der Website notwendig sind und genutzt werden, um persönliche Daten zu Analysezwecken, für Werbung oder andere eingebundene Inhalte zu ermitteln und weiterzugeben.
Diese nicht-notwendigen Cookies geben Informationen zu Ihrer Verwendung dieser Website an die entsprechenden Webdienste für soziale Medien, Werbung und Analysen weiter. Diese Webdienste führen die Informationen möglicherweise mit weiteren Daten zusammen, die Sie ihnen bereitgestellt haben oder die diese im Rahmen Ihrer Nutzung der Dienste gesammelt haben.
 Deutsche Übersetzung des Punktes 7 des Beitrages More cutting edge — Research tools for researchers — Oct 2020 von Aaron Tay mit geringfügigen Anpassungen
Deutsche Übersetzung des Punktes 7 des Beitrages More cutting edge — Research tools for researchers — Oct 2020 von Aaron Tay mit geringfügigen Anpassungen