malibu ist ein online Tool, welches ich vor ca. 6 Jahren angefangen habe zu entwickeln. Der Name „malibu“ passt gut zu PalMA, ein anderes Softwareprojekt von uns, und steht für Mannheim library utilities. Meine Motivation damals war die relevanten Informationen für ein Buch mit einer ISBN auf einer Seite zusammen zu sammeln um über die mögliche Erwerbung effizient entscheiden zu können. Neben der Erwerbungsauswahl hilft malibu auch bei der sachlichen Erschließung sowie beim Bestandsabgleich. Die Entwicklung des Tools geschieht transparent als Open Source auf GitHub und verschiedene Kolleg*innen haben mich dabei mit Ideen oder Anpassungen unterstützt. Im Folgenden sollen drei Anwendungsfälle von malibu für die bibliothekarische Praxis beschrieben werden.
Anwendungsfall 1: Informationen zu einem neu erschienen Buch
Häufig habe ich als Fachreferent die Aufgabe neue Bücher für die Bibliothek zu erwerben. Wenn ich nach der ersten Durchsicht bei einem potentiell interessanten Buch mehr Informationen erfahren möchte, dann gebe ich in malibu einfach die ISBN ein und es werden im Hintergrund Informationen dazu zusammen gesucht und auf einer Seite angezeigt:
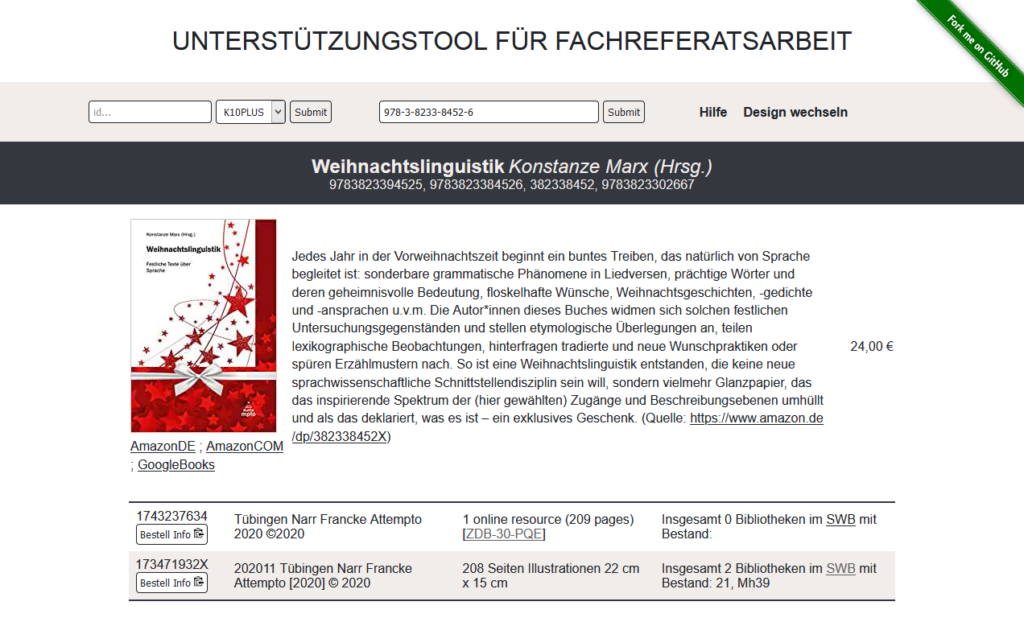
Auf einen Blick sieht man hier für das Buch den Klappentext, das Coverbild, eine Preisinformation und soweit vorhanden und auffindbar Bewertungen. Zudem werden für den SWB-Verbund die verschiedenen Ausgaben aufgelistet mit einer kurzen Bestandsangabe mit Bibliothekssigel. Desweiteren sind an verschiedenen Stellen Links für weiterführende Information eingefügt und auch am Ende der Seite sind nochmals weitere Links etwa zum Inhaltsverzeichnis angeführt.
Wenn ich dann einen Titel interessant finde und für die Bibliothek erwerben möchte, dann klicke ich auf den Button „Bestell Info“ um die wichtigsten Angaben in die Zwischenablage zu kopieren und schicke diese dann in einer E-Mail unter Angabe eines zu verwendenden Etats an die Kolleg*innen zum Bestellen weiter.
Anwendungsfall 2: RVK-Stellen und Verschlagwortung von einem Titel suchen
Bei der Sacherschließung lohnt es sich die bereits vorhanden Informationen zu verwenden. Teilweise ist in einem anderen Bibliotheksverbund bereits eine RVK-Stelle oder ein Schlagwort vergeben worden, oder aber es wurde eine DDC-Stelle für den Titel vergeben. Durch entsprechende Mappings und der hervorragender API des coli-conc Projektes kann man teilweise auch aus einer DDC-Stelle wieder direkt eine entsprechende RVK-Stelle bekommen, was insbesondere für englischsprachige Literatur interessant ist.
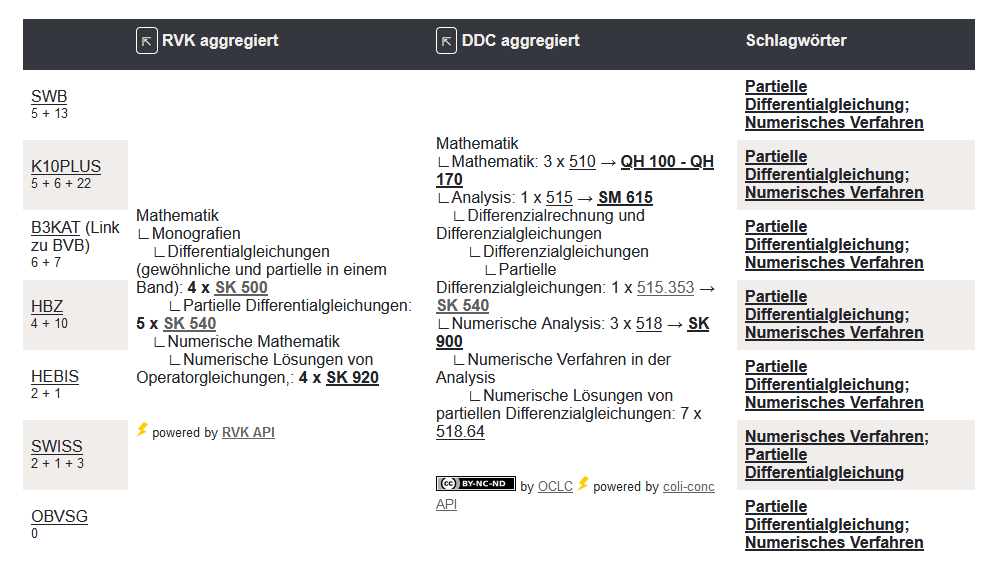
Die aggregierte Baumansichten hier bei den RVK- und DDC-Stellen sind noch relativ neu und über einen Klick des Icons in der entsprechenden Spaltenüberschrift umschaltbar. Die beschreibenden Informationen aus dem oberen Teil (vgl. erster Anwendungsfall) helfen bei der Sacherschließung ebenfalls häufig mit und können teilweise eine Autopsie am gedruckten Buch ersetzen (z.B. kann ich meistens die RVK-Stellen für die Aufstellung in der Bibliothek bereits bei der Bestellung mit angeben).
Anwendungsfall 3: Bestand von mehreren ISBNs prüfen
Bei jeder Suche nach einer einzelnen ISBN sieht man auch den Bestand der UB Mannheim speziell hervorgehoben, da ich das Tool hauptsächlich für uns entwickelt habe. Hierbei wird die SRU-Schnittstelle von unserer Alma-Instanz abgefragt. Prinzipiell kann man dies aber für andere Bibliotheken über entsprechende Schnittstellen ähnlich machen bzw. auch einfach die Bestandsinformationen in den Verbunddaten diesbezüglich auswerten. Zudem werden immer häufiger Bücher in ganzen Paketen gekauft insbesondere bei E-Books, so dass ein Bestandsabgleich einer Liste interessant ist. Genau für diesen Zweck gibt es den generischen Bestandsabgleich (Variante A) zusätzlich zu einem speziell für Mannheim:
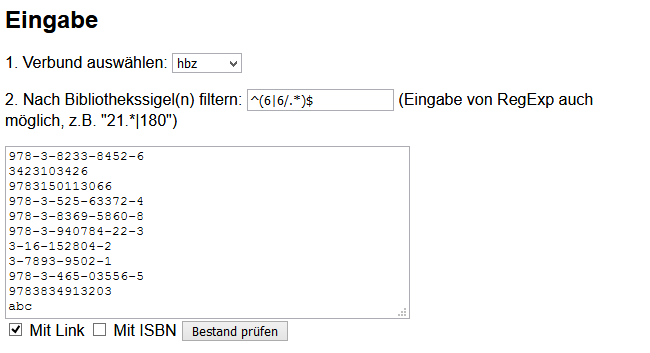
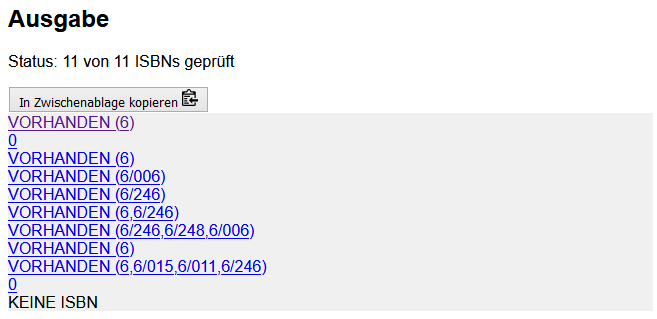
Abb. 3.a und 3.b: Bestandsabgleich für die ULB Münster inkl. aller Institutsbibliotheken von einer Liste von ISBNs mit malibu
In Abbildung 3 sieht man das Resultat für eine Liste von 11 ISBNs mit einem Bestandsabgleich im HBZ-Verbund gefiltert nach dem Bibliothekssigel von der ULB Münster (6) sowie allen Institutsbibliotheken (6/.*). Ein passender regulärer Ausdruck zum Filtern zu finden ist dann etwas Übungssache. Aus dem Resultat kann man sich beispielsweise die nicht vorhandenen Titel genauer ansehen oder auch diejenigen Titel, welche nur in den Institutsbibliotheken vorhanden sind.
Bei E-Book-Paketen bekommt man vom Verlag häufig eine Liste (z.B. als Excel-Datei) der enthaltenen E-Books meist auch mit den entsprechenden ISBNs. Den Inhalt dieser ISBN-Spalte kann man dann kopieren, beim Bestandsabgleich einfügen und durchlaufen lassen. Das Resultat kann dann auch wieder zurück in die Tabelle kopiert werden als Anreicherung um damit etwa in Excel auch Filterungen nach den lokalen Bestandsinformationen machen zu können. Dies kann hilfreich sein bei der Gesamtbeurteilung eines E-Book-Paketes oder auch um einzelne noch nicht vorhandene E-Books aus Pick-and-Choose-Paketen auszuwählen.
Bei größeren Mengen empfiehlt sich ggf. eine Aufteilung in kleinere Teile zum Prozessieren, da man ansonsten eventuell die SRU- oder Z39.50-Schnittstellen der Verbünde etwas stärker belastet.
Adaption und Ausblick
Ein paar weitere Ideen für neue Features oder einen Ausbau gibt es, aber es ist wahrscheinlicher, dass in nächster Zeit eher der Stand wie bisher fortgeführt wird mit nur kleinen Anpassungen. Auf jeden Fall bin ich immer an Feedback und Ideen interessiert.
Man kann malibu direkt online über die URL https://data.bib.uni-mannheim.de/malibu/ nachnutzen oder aber auch, da es Open Source ist, selbst aufsetzen und etwas an die lokalen Bedürfnisse weiter anpassen, wie es beispielsweise der Kollege aus Saarbrücken gemacht hat. Ebenfalls möglich ist es malibu als API für Batchabfragen zu nutzen, auch wenn dies eher ein Nebenprodukt von der bisherigen Entwicklung für die genannten Anwendungsfälle anzusehen ist. Nach- bzw. Mitbenutzung von malibu ist jederzeit erwünscht!
Dieser Blogbeitrag ist Teil der der Adventskalender Blogparade 24 Tools aus dem Netz im Einsatz für Bibliotheken #netzadvent2020: